We've previously talked about the negative effects that variability has on any sort of production process - in a basic queuing production model, where a product moves through a process step by step, variability is what prevents material from flowing smoothly between workstations, and forces expensive buffering (in the form of extra inventory, extra time, or extra capacity) to achieve a given production rate. Variability reduction is a key component of things like the Toyota Production System, as well as the Japanese method of ship production.
Because of its importance, it's worth looking closer at the idea of variability in a production process, and what it actually means to reduce it. This concept - that variability in a process can be understood and controlled - forms the basis of what’s known as statistical process control.
Shewhart and the origins of statistical process control
Statistical process control traces its origins to the 1920s and the work of physicist and engineer Walter Shewhart. Shewhart worked for Western Electric, the company that made telephone equipment for Bell Telephone, and was one of the early employees of Bell Labs [0]. Western Electric was one of the largest manufacturing operations in the US (by the 1930s, their Hawthorne Works [1] employed around 45,000 people), and it was while working there that Shewhart developed his ideas about process control.
These ideas would diffuse their way into company practice, and eventually be summarized in “The Western Electric Statistical Quality Control Handbook” in 1956 [2]. This book apparently became something of a bible in the field of quality control - it remains referenced almost 70 years later (despite being out of print), and copies that show up on Amazon invariably collect a series of 5-starreviews. Though the book is about the application of statistical methods to manufacturing processes, because it was written as a guide for practitioners (factory personnel charged with keeping quality high), it was, and is, an exceptionally lucid explanation of how process control works [3].
The basics of statistical process control
The basic idea behind process control is that all processes have some amount of variation in them - not even the most carefully controlled process can produce a completely uniform output. The example given is of writing the letter 'a' - if you write the letter repeatedly, no two 'a's will be exactly alike, no matter how good your penmanship. Slight variations in the paper, or in the lead composition, or to the thoughts running through your head, will all have tiny impacts on the path of the pen on the page, making each ‘a’ slightly different. Every process - whether it’s writing the letter ‘a’ or manufacturing engine parts - has some limit to its fidelity, beyond which the output will vary.
The point to be made in this simple illustration is that we are limited in doing what we want to do; that to do what we set out to do, even in so simple a thing as making a’s that are alike, requires almost infinite knowledge compared with that which we now possess. It follows, therefore, since we are thus willing to accept as axiomatic that we cannot do what we want to do and cannot hope to understand why we cannot, that we must also accept as axiomatic that a controlled quality will not be a constant quality. Instead, a controlled quality must be a variable quality. - Walter Shewhart, Economic Control of Quality of Manufactured Product
But not all variation is alike. We can break variation into two types - what Shewhart calls ‘natural’ and ‘unnatural’ variation. Natural variation is variation caused by tiny fluctuations in process conditions - slight fluctuations in temperature, or air pressure, or material tensile strength, or machine operator movements. This type of variation has no direct assignable cause - it consists of many small fluctuations in conditions that are beyond the scope of our knowledge, either because they’re fundamentally impossible to completely predict, or because the effort required to try to predict them would vastly exceed the potential benefits [4].
However, this type of variation can be understood statistically - accurately modeled by some sort of probability distribution with well-defined parameters. Consider a collection of air molecules - it’s effectively impossible to calculate the path of every single air molecule and every single collision between them. But their collective behavior can be modeled and understood.
Likewise, with a production process (say, a machine producing parts), it’s effectively impossible to trace down the cause of every microscopic fluctuation in dimensions, material strength, etc. (“Why is this part 12.0000003 inches in diameter but this one was 12.0000001 inches in diameter??”) But for variation caused by lots of small fluctuations, we can understand and model the output statistically (“This process has a mean of 12 inches and a standard deviation of +-.000005 inches.”)
The other type of variation is 'unnatural variation'. This is variation that we can assign a cause to. (“Why was this part 12 inches in diameter but this one was 11? Oh, it looks like the operator used the wrong setup jig for the second one.”)
If we can assign a cause to it, if we know why it occurs, then it's possible to eliminate it. The goal of statistical process control is to find and remove these sources of unnatural variation, and bring a process into a 'state of control', where fluctuations are determined by natural variation and thus act in a probabilistically well-defined manner. An 'out of control' process is one not aligning with the predictions of statistical theory, suggesting some cause of variation other than many small, randomly fluctuating factors.
Control charts
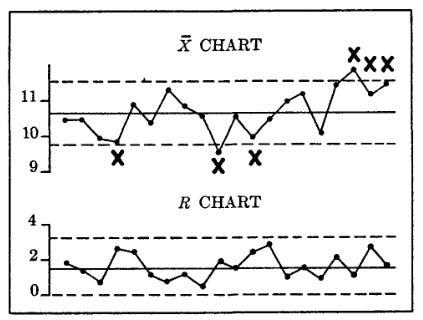
The main tool used in the book to diagnose sources of variation in a process is the control chart [5]. The control chart is a simple graph of a measurement of the output of a process over time - essentially a stretched out version of a simple frequency distribution. The two main types of control charts are the X-bar chart (which measures the average of a sample of some quantity such as length, diameter, impedance, etc. over time) and the R chart (which measures the range of a sample, the maximum minus the minimum over time.) For instance, the below chart shows X bar and R charts for the manufacturing of an amplifier. The charts measure the average gain, and the range of the gain, for samples of 5 amplifiers produced each day.
The upper and lower boundaries of the chart are defined by the mean of the process plus or minus 3 standard deviations (the origin of the idea of 'six sigma'), which the book provides a helpful table for calculating.
By using control charts, it's possible to determine whether a process is in control (variation is what would be expected probabilistically) or out of control - an out of control process will have many more values that approach or exceed the boundaries of the chart (typically indicated by x's), and will display noticeable patterns in the data. By examining the patterns of data in the charts, it's possible to diagnose and correct sources of variation that are being introduced. Here’s an example of how this might proceed:
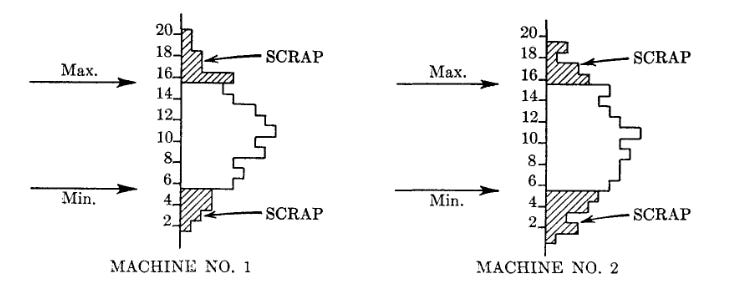
A certain shop was having trouble in meeting a dimensional specification. The engineer decided to take a sample of the parts coming from the process and group them together in the form of a frequency distribution.
This distribution showed that parts were failing to meet the specification on both the high and low sides. No apparent solution was found, however, by treating the data in this matter. The engineer then made a second attempt to analyze the trouble as follows:
These parts were being produced by two machines, each of which was supposed to perform the same function. The engineer decided to measure parts from the individual machines.
This also failed to give a solution to the problem. Both machines were in trouble and the distributions were very similar.
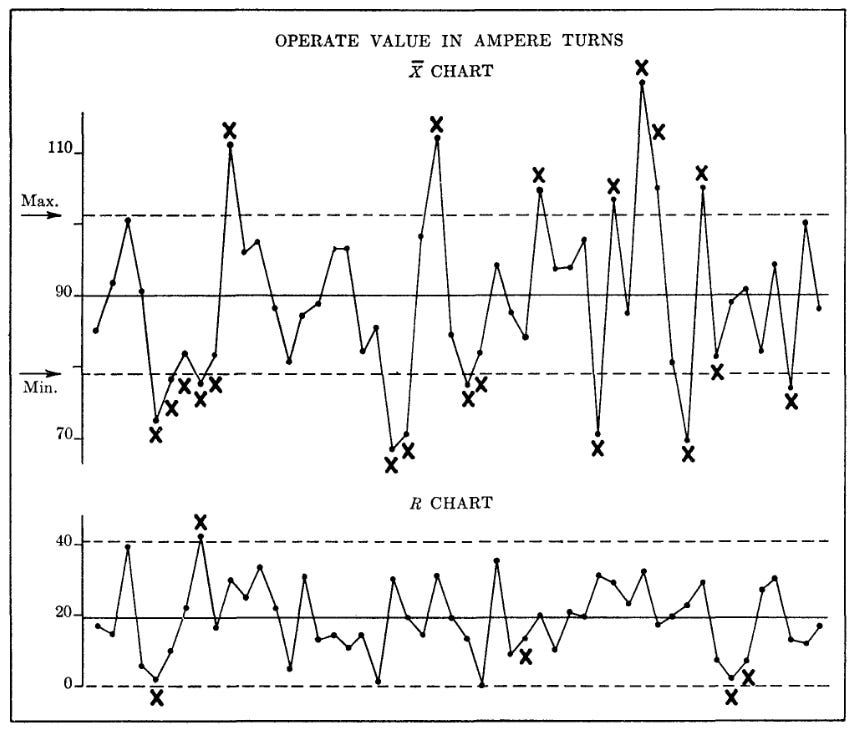
At this point the engineer decided to plot an X-bar and R chart. This required grouping the data into samples of 5 for each machine and plotting the average and range of each group of measurements in the order in which they were produced.
These charts showed immediately that there was a significant difference between the two machines. Machine No. 1 had a wide pattern on its R chart and the pattern was not in control. This meant that the machine was not behaving consistently. There was something about it that needed maintenance or repair.
When the Maintenance Department checked Machine No. 1 they found a worn bearing. When this was replaced, the R chart became much narrower and the product was no longer in trouble.
The cause of the trouble on Machine No. 2 was entirely different. This machine was already in good repair, as shown by the controlled pattern on its R chart. However, the center of the distribution on this machine was shifting back and forth, from the high side to the low side. This is shown by the out of control pattern on its X bar chart. This meant that the machine setter was either making poor settings or changing the setting too often.
When the machine setter was instructed to stop re-setting the machine on the basis of one or two measurements, and to use a control chart instead, the trouble disappeared also from Machine No. 2.
Getting to control
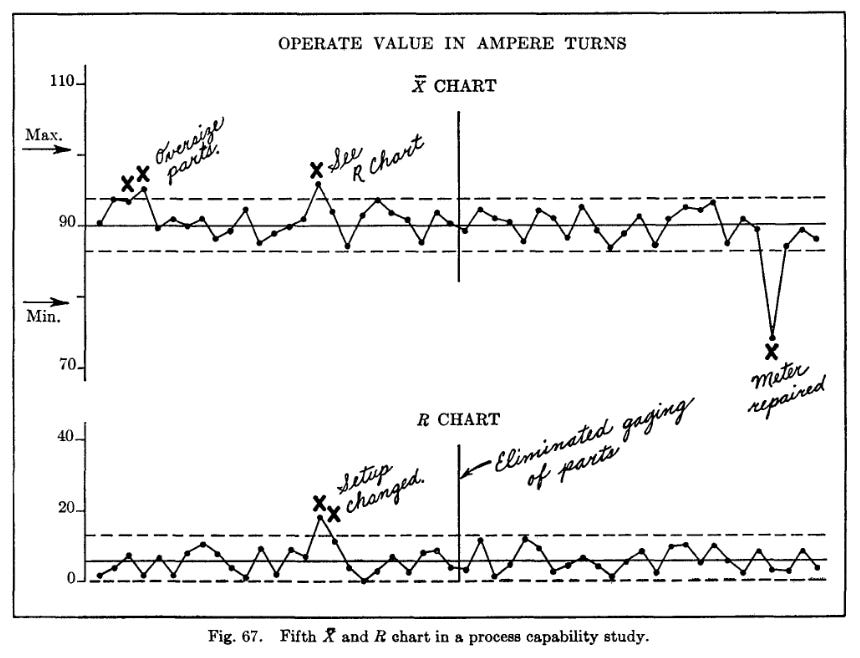
This sort of analysis works well for a process that is already under control - that, under normal circumstances, is producing in a narrow range of output, within desired tolerances, that is probabilistically predictable. But getting to that point isn't trivial - it requires a careful examination of the process (done via a "process capability study"), peeling back issues one by one until only ‘natural’ variation remains. The book gives an example of a process capability study done on the manufacturing of an electrical switch. The initial data looked like this:
One by one, sources of variation were eliminated. First, it was found that operators were making adjustments to the machine over time. Eliminating that practice revealed new patterns, which pointed to issues with the material holding. Fixtures were changed, and a magnetic material holding system was added. This change revealed yet another issue, that in many cases parts were being removed from the fixture without being given sufficient time to cool. An automatic timer was added to prevent this from happening. Fixing this revealed a new issue, that movement of the machine tool while it was operating caused parts to occasionally get bound in a fixture. Motors were relocated on the machine, which removed the problem.
At this point, the process was under control - all points were within expected variation, which in turn was within the allowable tolerance of parts. Any future deviations were now quickly noticed and addressed:
Getting to this state of control was an iterative process - each time something was fixed, more data was collected, revealing new causes that the previous issues had masked. Each iteration proceeded the same way - plot the data on a control chart, look for patterns, locate the issue and make any necessary process adjustments.
In both cases, the key tool for analyzing and understanding the process was the control chart. A large fraction of the book is devoted to interpreting control charts, and what various patterns of data indicate on them. A process in control will have most points near the mean (the center of the distribution), roughly evenly distributed on each side - too few points near the mean, or too many on one side, is an indication of unnatural variation. Different patterns on the control chart suggest different possible causes. For example, a gradual change in level of an X-bar chart (where the mean is slowly rising or falling over time) suggests a change was introduced that starts out affecting a few units, and then affects more and more units as time goes on - this could be caused by things like training (where operators gradually get more skilled), new material slowly being introduced, a maintenance program gradually being extended, etc. Other patterns in the data suggesting a cause are cycles (where values oscillate back and forth), bunching (several values in a row out of control) , or a sudden shift in level.
Design of experiments
Of course, getting an existing process as efficient as possible is only part of the goal. We also want to be able to explore new processes, methods, and techniques, and introduce them if they prove to be superior to our existing methods. The book provides methods for this as well, via “Design of Experiments.” The basic idea is simple - measure and compare the output of two (or more) processes, and compare them to see which one is superior.
At this point in the book, more advanced statistical concepts are introduced (ANOVA, statistical tests such as Bartlett’s or t-tests, etc.) But the recommended method of analysis remains plotting the data on a control chart. The reason is the same that control charts have been used so far - there may be assignable causes of variation lurking in one or both processes. Not only will other statistical tests often fail to reveal these, but their existence can often make the tests invalid (which, for instance, might require that both distributions are normal, or have the same variance.) Control charts, on the other hand, will make these issues apparent.
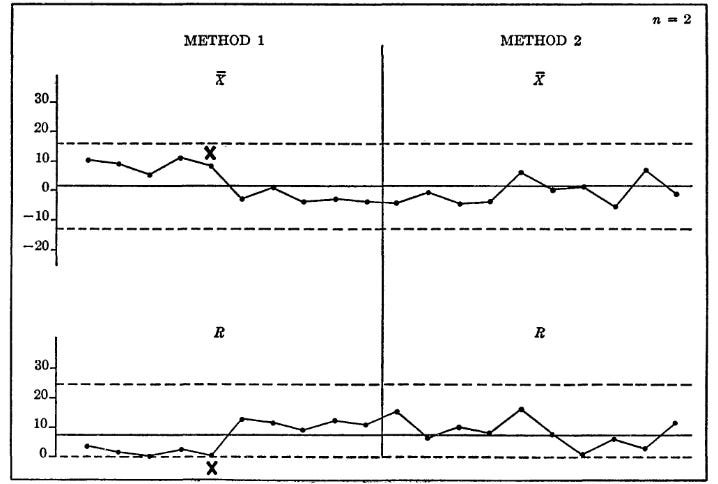
The book gives an example of a successful design of experiments, where an engineer compares two methods of producing an electrical component. The engineer collects data on both methods, and then runs several statistical tests, which are unrevealing. Both Bartlett’s and the F-test conclude that the variances can be considered equal, and the t-test and ANOVA were unable to rule out that the averages are equal.
However, plotting the data on a control chart revealed a pattern that the statistical tests had missed. The initial data suggests that method 1 is superior (lower range and higher output), but the output of method 1 shifts partway through the test (hence the conflicting results.) This was found to be caused by a part occasionally getting jammed in the machine. When this was found and fixed, the performance of method 1 was clearly superior (note that in this case, once the data was plotted on a control chart, it was clear that many of the assumptions of the statistical methods were incorrect.)
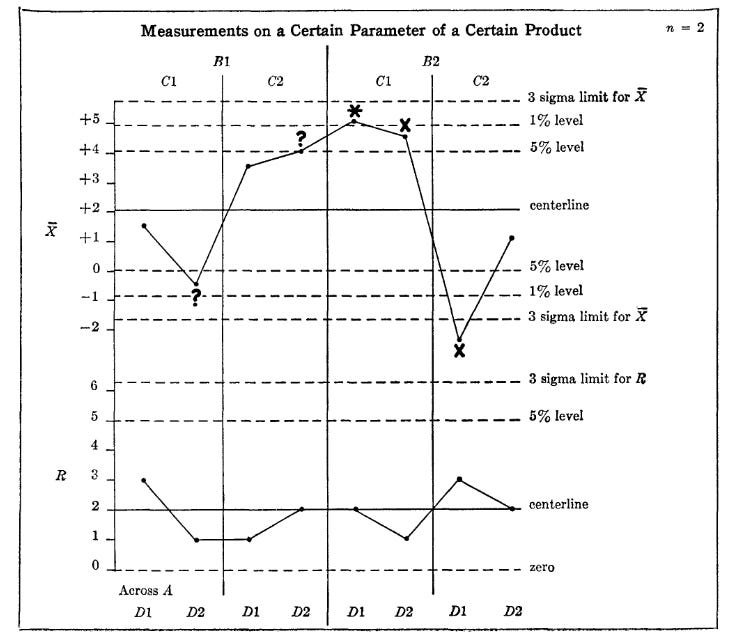
It’s even possible to use control charts for more advanced, multi-factor experiments, where you’re investigating several possible methods (and potential interactions between them) at the same time.
Control chart for a 4-factor experiment
The science of production
The book is essentially an explanation of how to do science in a manufacturing environment, with the goal of understanding the ‘laws of physics’ of some particular production process. Controlling a process first requires understanding it, which requires a scientific investigation of potential causes and their effects [6].
This sort of science has some distinct differences than science that explores the natural world. In many ways it’s easier - for one, you start with a lot of clues as to the likely causes at work. Manufacturing environments consist of similar sorts of processes arranged in similar sorts of ways, and will thus display similar sorts of behaviors. It’s this similarity that allows the book to suggest likely causes for patterns seen in control chart data, and which variables are likely to be important when making measurements [7]. For another, because you’re removing causes of variation over time, it’s much easier to find subtler, smaller, sneakier effects - instead of ‘controlling’ for a variable by complex statistical adjustments, you can control it simply by removing the thing that’s causing it.
But in some ways it’s harder. Science in the natural world typically gets to assume that the laws at work are unchanging. But a production environment, and the conditions affecting a process, are changing all the time. New workers are coming in, new machines are being installed, new products are being made, new suppliers are being brought on board, all while wear and tear is degrading the capability of machines. It thus takes constant intervention to understand the rules of the process and to keep it under control (I suspect this is why so many efficiency improvement systems focus on ‘continuous improvement’ - not merely to improve a process over time, but to prevent it from getting worse.) The whole concept of ‘control’ is that this effort never stops - monitoring, data collection, “science”, needs to be done constantly to watch for any new effects sneaking in.
It’s also made more difficult by the fact that this sort of science needs to get results with as little data as possible. Each ‘datapoint’ is a product that might have to be thrown away, or was produced less efficiently than it could have been, and thus loses the business money. The methods not only must work, but they must work quickly. (This is one reason for the emphasis on plotting the data, as it makes patterns readily apparent.)
But the basic precepts of science still apply - collect data, generate a hypothesis, test it with an experiment, and analyze the results. The book emphasizes, and gives instruction on, many practices that we’d consider “good scientific hygiene” (such as how to appropriately randomize data collection, how to ensure measurements are taken carefully, how to deal with outliers, and how to not be misled by statistics.) I suspect, based purely on the incentives at work, that the median process control engineer is a much better scientist than the median STEM PhD (there’s no “replication crisis” in manufacturing, there’s only your company losing market share or going out of business because your production process isn’t good enough.)
One limit to this sort of work is that it looks at processes in isolation. Later work would investigate the negative impacts of variation on sequences of processes, and form the basis of how things like Just-in-Time are able to work.
Comparison to construction
Construction, once again, is a world that pushes production optimization difficulties to 11. All the things that make science hard to do in a manufacturing environment are even harder in construction. For one thing, construction has a much higher rate of process changes - every new project means new workers, new environmental conditions, new materials, new construction details, etc. Not only does this introduce new causes to the process, but it changes (if only slightly) what the basic process is. As we’ve seen with learning curves, it only takes very small disruptions to ‘reset’ what workers know about a process [8], and these disruptions occur much more frequently in construction.
And what’s more, the subcontracted nature of a construction project means that instead of one sphere of control (a factory), where everything within it can be explored and manipulated, you have dozens of spheres of control, where each trade controls their own process but has limited ability to influence adjacent processes. The plumber can’t tell the HVAC technician what to do, neither of them can tell the framer what to do, etc. The GC has some ability to influence the whole process, but this generally stops short of the granular level of control (“we ran the numbers and you should be using an electric nailgun rather than pneumatic”) needed for really unpacking what’s going on with a process.
This makes it hard to do the sort of ‘process dialing in’ that statistical process control requires. As we saw, many potential inefficiencies are masked by other ones, and addressing them requires peeling each effect back one at a time. But in construction, many of the most significant issues will be things that exist between spheres of control [9] - if the framer laid out his joists in such a way that the plumber has no choice but to spend hours drilling through them, that’s going to swamp any potential inefficiencies that the plumber can actually control.
For another, most construction projects are just too short to really do the sort of data collection and process exploration that process control requires. Even a small X-bar chart and R chart might require 20 to 30 data points, but that might be a substantial fraction of a given construction task (depending on how granular you decide to get) - there might only be 20-30 (or even fewer) column base plates, or roof mounted HVAC units, or stair guardrails. By the time you’ve collected your data, you’re on to a new project with a slightly different process arrangement, and thus a slightly different set of ‘laws’.
And it’s obviously difficult to do a true ‘design of experiments’ in construction - there’s no real good way to compare two methods side by side and see which one is superior. Building two identical projects and using method A on one and method B on the other will almost never be feasible (much less building several with A and several with B and taking the average of each), and even using different methods within the same project isn’t trivial. And this is before you get to the incentive problems that push folks away from trying new methods.
Ultimately, what this means is that construction is rarely, if ever, truly in a state of control. But despite these difficulties, construction gets a lot closer to being able to implement process control methods than you might expect.
For one, the construction industry has a robust understanding of what the expected production rate for a given process is. Estimating guides like RSMeans are exhaustive compendiums of this sort of information, laying out expected crew size and production rates for thousands of different construction tasks. Production rates are built into the work schedule (as well as the contracts for the trades), and are monitored closely as throughout the job - deviations are monitored and dealt with (“we contracted for drywall to take 1 week per floor, but it’s taking you 2 weeks per floor, what’s going on?”) Work completion rates are closely tied to project financing (money for the project gets released as work gets completed), and it’s something that’s watched very closely.
Screenshot from a construction estimating guide
Which is not to say that these estimates are accurate, or that it doesn’t all go out the window due to circumstances that weren’t predicted (“whoops, we forgot to submit updated plans to the city so they’re closing down the jobsite, better push the schedule back a month”.) But it IS something which is paid close attention to.
There’s also a fairly robust understanding of what sort of variation in a process is acceptable. Documents like ASTM standards, design guides like the PCI manual or the ASCE steel manual, and code documents like the IRC or IBC all map out how much variation is allowed for various products and processes (in the form of allowable tolerances), often quite exhaustively. And a variety of inspectors (jurisdiction building inspectors, structural special inspectors, threshold inspectors, independently hired QC inspectors, factory inspectors) are in place to verify the work is being done within allowable tolerances (though in many cases this inspection is another “sphere of control” that other folks have limited influence over - if I fail the city electrical inspection, I may be forced to wait for whenever they’re available to come back out and see the corrected work.)
Future of construction process control
There’s also good reason to think we’ll see even more use of these sorts of methods in the future. One obvious way would be increased use of prefabrication (though it also indicates a likely upper bound for how much they can potentially reduce costs - if it was more than the increased cost of factory overhead, logistics and transportation, we’d already be seeing this everywhere.) The more work that gets done off-site in a controlled factory environment (for whole building modules, but also things like prefabricated cladding panels), the more it’s possible to take advantage of process control. People are perennially predicting the rise of prefab, but there’s a few trends (declining labor availability, the desire for improved energy performance, startups using novel ways to get around the logistics difficulties) which might make it ‘stick’ this time, at least to some extent.
Another, perhaps more interesting path, is by way of the recent slew of construction data capture startups. These use a variety of methods (drones, phones, LIDAR, 360 degree cameras, hardhat mounted cameras) to record and analyze jobsite progress. You can imagine this technology (and the AI that powers it) getting good enough that it’s capable of measuring the precise location of every component that gets placed, allowing for not only an extremely accurate measurement of production rates, but being able to quickly recognize production deviations (“it looks like the nails in this sheathing are at 6” on center instead of 4”, did the framer get the most recent set of drawings where this was changed?”) [10]. So I actually expect these sorts of methods to gain even more currency in the future.
[0] - For those keeping score, this adds "a substantial fraction of modern manufacturing improvements" to the list of achievements of Bell Labs.
[1] - The Hawthorne Works was the site of a famous organizational study (performed by, among others, Vannevar Bush) that discovered what became known as the "Hawthorne Effect" - that the act of studying people, regardless of what your specific intervention is, will cause their performance to improve.
[2] - Written, in large part, not by Shewhart but by Bonnie Small.
[3] - From the preface of the book: "The book is written in non-technical language, and no attempt has been made to write for the professional statistician or the mathematician. The techniques described are essentially those which have been used in all types of industry since their development during the 1920's by Dr Shewhart."
[4] - What's natural/assignable and what's not is in some ways a function of the process itself, and what it's economic to try to predict. Semiconductor manufacturing, for instance, requires a much greater level of control over the process (and thus a much greater measurement and understanding of the causes of variation) than, say, car manufacturing.
[5] - The idea that plotting the data is an important tool for understanding it is perhaps most easily seen with Anscombe’s Quartet, 4 datasets with similar statistical properties which nonetheless show very different patterns.
[6] - This process of systematically addressing causes one by one, perhaps not coincidentally, resembles this anecdote from Feynmans’ Cargo Cult Science:
“For example, there have been many experiments running rats through all kinds of mazes, and so on—with little clear result. But in 1937 a man named Young did a very interesting one. He had a long corridor with doors all along one side where the rats came in, and doors along the other side where the food was. He wanted to see if he could train the rats to go in at the third door down from wherever he started them off. No. The rats went immediately to the door where the food had been the time before.
The question was, how did the rats know, because the corridor was so beautifully built and so uniform, that this was the same door as before? Obviously there was something about the door that was different from the other doors. So he painted the doors very carefully, arranging the textures on the faces of the doors exactly the same. Still the rats could tell. Then he thought maybe the rats were smelling the food, so he used chemicals to change the smell after each run. Still the rats could tell. Then he realized the rats might be able to tell by seeing the lights and the arrangement in the laboratory like any commonsense person. So he covered the corridor, and, still the rats could tell.
He finally found that they could tell by the way the floor sounded when they ran over it. And he could only fix that by putting his corridor in sand. So he covered one after another of all possible clues and finally was able to fool the rats so that they had to learn to go in the third door. If he relaxed any of his conditions, the rats could tell.
Now, from a scientific standpoint, that is an A‑Number‑l experiment. That is the experiment that makes rat‑running experiments sensible, because it uncovers the clues that the rat is really using—not what you think it’s using. And that is the experiment that tells exactly what conditions you have to use in order to be careful and control everything in an experiment with rat‑running.
I looked into the subsequent history of this research. The subsequent experiment, and the one after that, never referred to Mr. Young. They never used any of his criteria of putting the corridor on sand, or being very careful. They just went right on running rats in the same old way, and paid no attention to the great discoveries of Mr. Young, and his papers are not referred to, because he didn’t discover anything about the rats. In fact, he discovered all the things you have to do to discover something about rats. But not paying attention to experiments like that is a characteristic of Cargo Cult Science.”
[7] - Though this will be a function of what sort of production you’re doing. The “universe of possible causes” in a machine shop is much different than in a semiconductor fab (though in both cases, similar manufacturers will likely face similar sorts of issues.) The more you push into new methods of production, the more you’re forced to consider new types of possible causes.
[8] - An example from semiconductor manufacturing: one company in the 70s found that a slight process change (introducing 3” wafers alongside 2” wafers) dropped their production yields from 90% to 50%. The culprit? The wafers were being damaged during handling, because the workers had adapted their movements for the smaller wafers.
[9] - An example of how this manifests itself - lean publications often disdain the use of “expediters”, people whose job it is to make sure material for critical orders moves through the process. Construction not only has a large number of folks that do this (project managers), they’re essential to making sure anything gets built at all.
[10] - They may not be attempting this idea specifically, but I suspect some version of the flywheel of “use data to train a better AI, which gets us a better product, which gets us more customers and more data, which gets a better AI” is the idea behind a lot of these datacapture startups with “AI” in their name.
Great article as always. If folks are not aware, there are now standards that are associated with pre-fab offsite construction for different assemblies. ICC has two ( https://www.iccsafe.org/advocacy/safety-toolkits/offsite-construction/ ) and ASSE has one ( https://assewebstore.com/asse-lec-2012-2021a-download/ ) specific to plumbing and mechanical systems. It wasn’t long ago that when a PE needed a rooftop air handler, they would design the entire system themselves by specifying individual compressors, coils, fans, etc. Today, they select a packaged RTU. A similar trend is starting up with packaged plumbing system available from manufacturers. Will be interesting how and where GC's and engineers adopt the concept.




Great article as always. If folks are not aware, there are now standards that are associated with pre-fab offsite construction for different assemblies. ICC has two ( https://www.iccsafe.org/advocacy/safety-toolkits/offsite-construction/ ) and ASSE has one ( https://assewebstore.com/asse-lec-2012-2021a-download/ ) specific to plumbing and mechanical systems. It wasn’t long ago that when a PE needed a rooftop air handler, they would design the entire system themselves by specifying individual compressors, coils, fans, etc. Today, they select a packaged RTU. A similar trend is starting up with packaged plumbing system available from manufacturers. Will be interesting how and where GC's and engineers adopt the concept.
Thank you Brian. I enjoyed reading the review and learned new concepts.